
Introduction
Sensei is a distributed data system that was built to support many product initiatives at LinkedIn.com, e.g. LinkedIn Signal and the LinkedIn Homepage. It is foundation to the LinkedIn's search and data infrastructure.
Sensei is both a search engine and a database. Sensei is designed to query and navigate through documents with parts that contain text and are unstructured, as well as parts containing meta information that have well-formed structures.
If you know RDBMS
A good start to understand Sensei is by comparing it to traditional RDBMSs'. This provides a quick reference point to the common feature-sets as well as the differences.
Query Language
RDBMS
SQL is the de-facto way for querying in the RDBMS world.
Sensei
In the Sensei world, the query language is BQL, which is a SQL-variant that exposes the Sensei specific functionalities.
Interface with data in a program
RDBMS
To interface with your data programmatically, the JDBC API is foundation to most Java based frameworks.
Sensei
With Sensei, we offer a variety of client libraries, e.g. Java, Python etc. over a JSON/Http Rest api. Click here for details.
Creating a table/store
RDBMS
CREATE TABLE SQL statement is issued to RDBMS
Sensei
A Sensei schema is defined in the schema.xml in the configuration file. See example.
Data population
RDBMS
Data are pushed into RDBMS via INSERT, DELETE and UPDATE SQL commands
Sensei
Data are pulled into Sensei via Gateways, which defines a flowing stream of data events. See details
Architecture Diagram
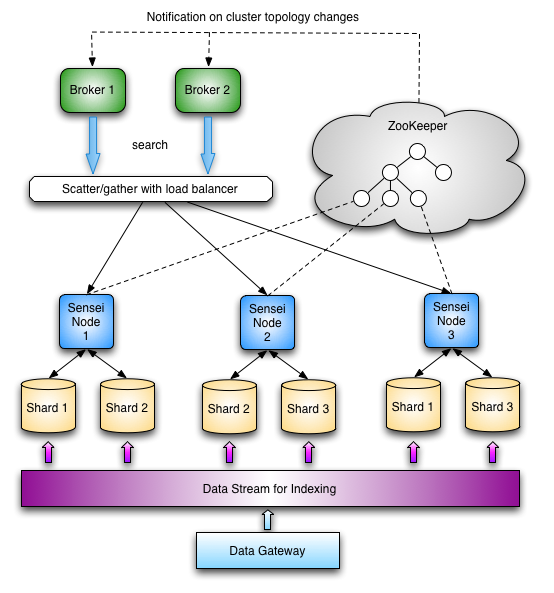
Design considerations
- data:
- Fault tolerance/Availability - when one replication is down, data is still accessible via other replicas
- Durability - N copies of data is stored so you have N backups
- Through-put - Parallelizable request-handling on different nodes/data replicas, designed to handle web-scale traffic
- Consistency - Eventual consistent, your data replicas will never go outta wack!
- Data recovery - each shared/replica is noted with a watermark for data recovery
- Large dataset - designed to handle 100s millions - billions of rows
- horizontally scalable:
- Data is partitioned - so work-load is also distributed
- Elasticity - Nodes can be added to accommodate data growth
- Online expansion - Cluster can grow while handling online requests
- Online cluster management - Cluster topology can change while handling online requests
- Low operational/maintenance costs - Push it, leave it and forget it.
- performance:
- low indexing latency - real-time update supported, e.g. when data are added to the system, they become part of the query-able corpus right away.
- low search latency - millisecond query response time
- low volatility - low variance in both indexing and search latency
- customizability:
- plug-in framework - custom query handling logic
- routing factory - custom routing logic, default: round-robin
- index sharding strategy - different sharding strategy for different applications, e.g. time, mod etc.
- relevance model