
Sensei & Hadoop
Batch indexing on Hadoop, load into Sensei and run queries.
Hadoop
Apache Hadoop has become an important part of data infrastructure solutions in the industry. In enterprises, Hadoop is where large amounts of data are stored, aggregated and transformed via Map-Reduce jobs.
For convenience and efficiency, it is a good idea to let Hadoop perform batch-indexing by leveraging its storage and parallelized computation capacities.
Sensei Hadoop integration
We have written a fast Map-Reduce job by taking data from Hadoop and batch build indexes given a Sensei schema and sharding strategy.
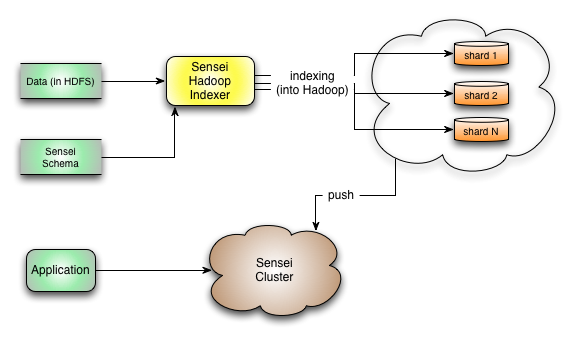
The following diagram illustrates this indexing process:
Layout of source packages
We explain the functionality of Sensei Hadoop indexing and its workflow through the layout of sensei hadoop indexing source packages:
- com.senseidb.indexing.hadoop.job;
This package contains the job configuration file loading classes.
- com.senseidb.indexing.hadoop.keyvalueformat;
This package specifies the data format (key, value) used in hadoop-indexing system.
- com.senseidb.indexing.hadoop.map;
This package contains underlying Sensei Hadoop Mapper file and also a dummy Converter to deal with preprocess of input record.
- com.senseidb.indexing.hadoop.reduce;
This package contains Hadoop Reduer and Combiner files.
- com.senseidb.indexing.hadoop.util;
Util package has all kinds of naming configuration files and utility tools.
Car Demo
To be consistent, we also use the car demo data to describe our hadoop indexing system. Sensei package comes with a car demo hadoop-indexing example and it mainly has four simple files. The first one "CarDemo.java" is a simple main class providing a starting point for running the program. "CarMapInputConverter.java" is a sample converter class to convert the input data record for map job. "CarShardingStrategy.java" is another class to provide a user-specified sharding strategy. Also we need a configuration file to help Sensei Hadoop indexer to configure all the rest properties, a sample configuration file can be found at "$SENSEI_HOME/example/hadoop-indexing/conf/JobCarDemo.job". To run the demo, simple compile and package the project into an executable jar file called CarDemo.jar. Then run "hadoop jar CarDemo.jar". (You need to specify the job configuration file location in CarDemo.java, and upload the schema file into the HDFS system before running, and also the location of the schema file should be set in the configuration file)
(1) Set up a local hadoop running environment (pseudo Hadoop cluster)
Following this page the "pseudo hadoop cluster" part in Apache Hadoop project can help to setup a local pseudo hadoop cluster very easily in less than 5 minutes. The main steps are as follows,
- Dowload the stable release of hadoop. Be sure to download the 0.20.2 version, otherwise some compatibility issue may happen;
- Change the configurations as in the "Single Node Setup" page pseudo hadoop cluster setup part mentioned above;
- Make sure "ssh localhost" is working;
- Edit the file conf/hadoop-env.sh to define at least JAVA_HOME to be the root of your Java installation;
- Start the HdFS file system and Hadoop daemons;
After the local pseudo Hadoop cluster is running, we can check the following two pages for what's in the HDFS, and what jobs are running.
- NameNode - http://localhost:50070/
- JobTracker - http://localhost:50030/
Now you have a Hadoop cluster running successfully! We will use $HADOOP_HOME to refer to the location of the Hadoop you just installed.
(2) Use hadoop to build index
Before using the local Hadoop to build the index, we need to upload the schema.xml file and the input data into the local HDFS system:
$HADOOP_HOME/bin/hadoop fs -mkdir conf $HADOOP_HOME/bin/hadoop fs -put $SENSEI_HOME/example/cars/conf/schema.xml conf/ $HADOOP_HOME/bin/hadoop fs -mkdir data $HADOOP_HOME/bin/hadoop fs -put $SENSEI_HOME/example/cars/data/cars.json data/
After uploaded the schema.xml file and the input data (cars.json), you can go to "http://localhost:50070/nn_browsedfscontent.jsp" to check if there are there in the local HDFS. These files will be used by your Hadoop job in the following steps.
To build index through Sensei-hadoop-indexer, simply write your own job files just as the car demo files (Java files with main function as entry point, and also specifying where the configuration file is, sharding strategy, etc.), and then package it as a runnable jar file (e.g., example.jar) to execute:
cd $SENSEI_HOME/example/hadoop-indexing/ mvn package cp target/sensei-example-hadoop-1.0.0-SNAPSHOT-jar-with-dependencies.jar CarDemo.jar $HADOOP_HOME/bin/hadoop jar CarDemo.jar
Your main class actually specified the location of the job configuration file in local filesystem. In the Car demo configuration, we specified the input data path and schema.xml file location in HDFS, which we just uploaded in the step above.
The sample job configuration file used in Car Demo case:
type=java job.class=com.senseidb.indexing.hadoop.demo.CarDemo mapreduce.job.maps=2 sensei.num.shards=2 mapred.job.name=CarDemoShardedIndexing # if the output.path already exists, delete it first sensei.force.output.overwrite=true # adjust this to a small one if mapper number is huge. default is 50Mb = 52428800 sensei.max.ramsize.bytes=52428800 ############# path of schema for interpreter ############# ##### TextJSON schema Sample (car demo) absolute path ###### sensei.schema.file.url=conf/schema.xml ############ Input and Output ################## ####### Text JSON data (car demo) ##### read.lock=data/cars.json sensei.input.dirs=data/cars.json ######## Output configuration ###### write.lock=example/hadoop-indexing/output sensei.output.dir=example/hadoop-indexing/fileoutput ######## Index output location ###### sensei.index.path=example/hadoop-indexing/index ############# schemas for mapper input ################ sensei.input.format=org.apache.hadoop.mapred.TextInputFormat ############## Sharding strategy ################ sensei.distribution.policy=com.senseidb.indexing.hadoop.demo.CarShardingStrategy ############# Converter for mapper input (data conversion and filtering) ########## sensei.mapinput.converter=com.senseidb.indexing.hadoop.demo.CarMapInputConverter ############# Analyzer configuration for lucene ############### sensei.document.analyzer=org.apache.lucene.analysis.standard.StandardAnalyzer sensei.document.analyzer.version=LUCENE_30
The sample output when we run the hadoop job:
[sguo@sguo-ld hadoop-indexing]$ /local/test/hadoop-0.20.2/bin/hadoop jar CarDemo.jar 11/12/22 19:35:09 INFO job.MapReduceJob: dirs:data/cars.json 11/12/22 19:35:09 INFO job.MapReduceJob: length after split:1 11/12/22 19:35:09 INFO job.MapReduceJob: path[0] is:data/cars.json 11/12/22 19:35:09 INFO job.MapReduceJob: Adding schema file: conf/schema.xml 11/12/22 19:35:09 INFO job.MapReduceJob: mapred.input.dir = hdfs://localhost:9000/user/sguo/data/cars.json 11/12/22 19:35:09 INFO job.MapReduceJob: mapreduce.output.fileoutputformat.outputdir = hdfs://localhost:9000/user/sguo/example/hadoop-indexing/fileoutput 11/12/22 19:35:09 INFO job.MapReduceJob: mapreduce.job.maps = 2 11/12/22 19:35:09 INFO job.MapReduceJob: mapreduce.job.reduces = 2 11/12/22 19:35:09 INFO job.MapReduceJob: 2 shards = -1@example/hadoop-indexing/index/0@-1,-1@example/hadoop-indexing/index/1@-1 11/12/22 19:35:09 INFO job.MapReduceJob: mapred.input.format.class = org.apache.hadoop.mapred.TextInputFormat 11/12/22 19:35:09 INFO job.MapReduceJob: mapreduce.cluster.temp.dir = ./tmp/hindex/ 11/12/22 19:35:10 INFO mapred.FileInputFormat: Total input paths to process : 1 11/12/22 19:35:10 INFO mapred.JobClient: Running job: job_201112221928_0001 11/12/22 19:35:11 INFO mapred.JobClient: map 0% reduce 0% 11/12/22 19:35:28 INFO mapred.JobClient: map 44% reduce 0% 11/12/22 19:35:31 INFO mapred.JobClient: map 76% reduce 0% 11/12/22 19:35:34 INFO mapred.JobClient: map 100% reduce 0% 11/12/22 19:35:56 INFO mapred.JobClient: map 100% reduce 50% 11/12/22 19:35:59 INFO mapred.JobClient: map 100% reduce 100% 11/12/22 19:36:01 INFO mapred.JobClient: Job complete: job_201112221928_0001 11/12/22 19:36:01 INFO mapred.JobClient: Counters: 18 11/12/22 19:36:01 INFO mapred.JobClient: Job Counters 11/12/22 19:36:01 INFO mapred.JobClient: Launched reduce tasks=2 11/12/22 19:36:01 INFO mapred.JobClient: Launched map tasks=2 11/12/22 19:36:01 INFO mapred.JobClient: Data-local map tasks=2 11/12/22 19:36:01 INFO mapred.JobClient: FileSystemCounters 11/12/22 19:36:01 INFO mapred.JobClient: FILE_BYTES_READ=9142907 11/12/22 19:36:01 INFO mapred.JobClient: HDFS_BYTES_READ=4960962 11/12/22 19:36:01 INFO mapred.JobClient: FILE_BYTES_WRITTEN=9159180 11/12/22 19:36:01 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=4563379 11/12/22 19:36:01 INFO mapred.JobClient: Map-Reduce Framework 11/12/22 19:36:01 INFO mapred.JobClient: Reduce input groups=2 11/12/22 19:36:01 INFO mapred.JobClient: Combine output records=4 11/12/22 19:36:01 INFO mapred.JobClient: Map input records=15000 11/12/22 19:36:01 INFO mapred.JobClient: Reduce shuffle bytes=4579540 11/12/22 19:36:01 INFO mapred.JobClient: Reduce output records=2 11/12/22 19:36:01 INFO mapred.JobClient: Spilled Records=8 11/12/22 19:36:01 INFO mapred.JobClient: Map output bytes=20803338 11/12/22 19:36:01 INFO mapred.JobClient: Map input bytes=4957569 11/12/22 19:36:01 INFO mapred.JobClient: Combine input records=15000 11/12/22 19:36:01 INFO mapred.JobClient: Map output records=15000 11/12/22 19:36:01 INFO mapred.JobClient: Reduce input records=4 Total time: 51841
(3) Bootstrap a running Sensei server from index built by hadoop
To bootstrap Sensei index, we firstly start a Sensei server with no document indexed.(remember to add "sensei.indexer.copier=hdfs" property in the sensei.properties file):
To make sure this Sensei server does not index any document, we create an empty file in $SENSEI_HOME/example/cars/data/empty.json,
We modify the property file in $SENSEI_HOME/example/cars/conf/sensei.properties, and set sensei.gateway.path = example/cars/data/empty.json, then we start the sensei.
In $SENSEI_HOME:
./bin/start-sensei-node.sh example/cars/conf/
Now we go to localhost:8080 in web browser, click apply then click execute, we will get the current total doc number is 0 in index:
{
"time": 5,
"hits": [],
"facets": {},
"totaldocs": 0,
"numhits": 0,
"numgroups": 0,
"tid": -1,
"parsedquery": ""
}
After Sensei is started, we specify the location and port of the running Sensei Server, and also the index location in HDFS built in the first step. In this case, the generated index folder is located in hdfs://localhost:9000/sensei-app/example/hadoop-indexing/index . We bootstrap this server by doing the folloing:
In $SENSEI_HOME:
./bin/load-index -s localhost -p 8080 hdfs://localhost:9000/sensei-app/example/hadoop-indexing/index
After the boostrap is finished, let's check the localhost:8080 webpage again, and click apply, then click execute to search, we get the following at the bottom of the search result, the number of documents has been increased from 0 to 15000 since we "appended" the bootstrapped index into the current one:
In $SENSEI_HOME:
{
"facets": {},
"totaldocs": 15000,
"numhits": 15000,
"numgroups": 0,
"tid": -1,
"parsedquery": "*:*"
}
Data warehousing
Other than this convenience, there are some other immediate benefits, for example: data-warehousing.
Traditionally, data-warehousing solutions are built on the RDBMS. In the current era of information explosion, traditional solutions are no longer feasible given the amount of data.
Recently, technologies such as Apache's Pig and Hive projects have been developed in solving this problem by translation a SQL-like query language into Map-Reduce jobs over Hadoop. This made data-warehousing on large datasets possible.
In scenarios where data-scientists work on a set of data files for some project, the underlying dataset do not change between queries issued by subsequent Pig/Hive scripts into Hadoop, which means much of the work is redundant and wasteful. It would make sense by writing a data-preparation job by aggregating all parts of data of interest, and launch the batch indexing job to produce Sensei shards. Once loaded into Sensei, fast queries over BQL can be executed and this avoids paying a Map-Reduce cost per query.
Javadoc
For Javadoc reference, go to: Javadoc »