
Indexing & Gateway
Getting data into Sensei.
Data Events
Data events are units of indexing activities. Each data event is a tuple of (type,data,version). (versions are interpreted by Gateway semantics)
Types of data events:
- add (default) - inserts data into Sensei
- delete - deletes data from Sensei
Examples of data events
Add event:
{"type":"add","data":{"id":1,"contents":"sensei is cool","attrib":"opensource"}}
since add is the default event type, this is equivalent to:
{"id":1,"contents":"sensei is cool","attrib":"opensource"}
for add events with the same id, newer events overwrite existing events
Delete event:
{"type":"delete","id":1}
If no such event exists, this event is a no-op.
We will be supporting partial updates in the next release.
Data Stream
Stream of data events that Sensei consumes from via Gateways.
Some properties of Data Streams:
- Versioned - each event on the stream has a monotonically increasing value indicating a unique point in the stream
- Ordered - ordering of all events should reflect the semantics of the application
Some examples of data streams:
- Twitter stream
- Activity tracking data, e.g. LinkedIn profile creation and update events
- Server logs
Gateway
Gateways are integration components between Sensei and Data Streams. Gateways serve the following purposes:
- Read data events from data streams and proxy between Sensei and the data stream
- Interpret version semantics of data events read from the data stream
The following diagram illustrates how gateways fit into Sensei:
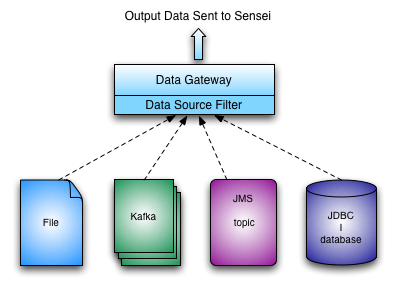
Sensei comes with the following pre-written gateways:
-
File - each line is a data event, and line number is the version.
Configuration:
sensei.gateway.class=com.senseidb.gateway.file.LinedFileDataProviderBuilder sensei.gateway.file.path = <file-name> -
JMS - each message is a data event,
System.nanoTime()is used as version.Configuration:
sensei.gateway.class=com.senseidb.gateway.jms.JmsDataProviderBuilder sensei.gateway.jms.topic = <topic name> sensei.gateway.jms.clientId = <client id> sensei.gateway.jms.topicFactory = <topic factory class name> sensei.gateway.jms.connectionFactory = <connection factory class name> -
JDBC - each element in the ResultSet is a data event, developer implements version semantics.
Configuration:
sensei.gateway.class=com.senseidb.gateway.jdbc.JdbcDataProviderBuilder sensei.gateway.jdbc.url=<url name> sensei.gateway.jdbc.username=<username> sensei.gateway.jdbc.password=<password> sensei.gateway.jdbc.driver=<driver class name> sensei.gateway.jdbc.username=<url name> sensei.gateway.jdbc.username=<url name> jdbc.adaptor.class=<The class name of the custom jdbc adapter> Kafka - each message is a data event, and offset is the version.
Configuration:
sensei.gateway.class=com.senseidb.gateway.kafka.KafkaDataProviderBuilder sensei.gateway.kafka.zookeeperUrl=<zookeeper Url> sensei.gateway.kafka.consumerGroupId=<consumerGroupId> sensei.gateway.kafka.topic=<kafka topic name> sensei.gateway.kafka.timeout=<connection timeout> sensei.gateway.kafka.batchsize=<kafka batch size>
Custom Gateways
Data comes in from many different sources. While we are busy supporting more sources by writing Gateways, you can write your own custom gateways.
To write your own custom gateway, follow the following steps:
- Implement SenseiGateway interface:
public class MyAwesomeGateway
extends SenseiGateway { public MyAwesomeGateway(Configuration conf) { super(conf); } @Override public StreamDataProvider buildDataProvider( DataSourceFilter dataFilter, String oldSinceKey, ShardingStrategy shardingStrategy, Set partitions) throws Exception { // build a StreamDataProvider instance ... } @Override public Comparator getVersionComparator() { // tell us versioning semantics ... } } -
Like any other extensions to Sensei, build it into a jar and copy it into the
conf/extdirectory, whereconfcontains configuration files. -
Edit
sensei.propertiesto configure your Gateway:sensei.gateway.class = <custom gateway class> # parameters set to the gateway sensei.gateway.param1 = <value1> sensei.gateway.param2 = <value2>
Now when you start Sensei, e.g.
./bin/start-sensei-node.sh <conf-dir>To query Sensei, go to: Clients & APIs »
Batch indexing
Batch indexing over Hadoop is supported by Sensei. Go to: Hadoop Bootstrap »