
Cluster Overview
How Sensei scales horizontally
Replications
There are three important reasons for data replication in a distributed data system:
- Availability
- Through-put/request scalability
- Data Durability
Availability:
In a high-traffic internet service, what can go wrong will go wrong...very often! In a distributed systems setting, where the system is composed of many physical machines, the likelihood of failure increases with the number of machines.
By having a level of redundancy makes the system tolerant to faults, because at times of system failures, a replication can take over handling the request.
Through-put/request scalability
Having replications not only helps at times of failures, while serving normal traffic, replicas divide up the requests and share the workload. For example, if the system can handle 100 requests per second, having 3 replications would be able to handle 300 requests per second.
Data Durability
This is perhaps the most important guarantee any data system must provide: data cannot be lost.
Having replications of the actual data provides N copies of your data (N - number of replications).
Sharding
Shards are also called partitions. As size of the data corpus increases, so does query latency. This is a fairly easy assertion to understand. In designing large data systems, we must assume there is no upper-bound for the number of documents in corpus.
By dividing the corpus into smaller shards, we are able to divide query-time computation cost into smaller and parallel work units via a scatter-gather pattern. For example, we can reduce the problem of querying against a corpus with 100 million documents into 10 concurrent queries against 10 shards, each containing 10 million docs (scatter), and then merge the result set (gather).
Sensei cluster
A Sensei cluster consists of nodes and shards. Both nodes and shards are identified by an unique integer. Each Sensei node can consist N shards.
For example, given 3 Sensei nodes: {N1, N2, N3}, and 3 shards: {S1, S2, S3}, with the following cluster topology:
- N1 - {S1, S2}
- N2 - {S2, S3}
- N3 - {S1, S3}
See the following diagram for an example of a large Sensei cluster:
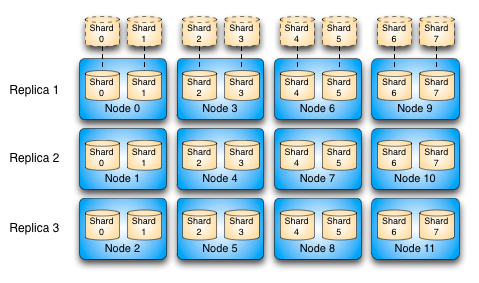
Cluster configuration
In sensei.properties file, edit the following properties:
# node id sensei.node.id=1 # comma separated list of partitions this node works with sensei.node.partitions=0,1
More information on Sensei configuration, go to Sensei Configuration »
Under the hood
Each Sensei node reports to Zookeeper, our cluster manager, its state and which shards it has. Zookeeper propagates this information through-out the entire cluster, especially to the brokers. The brokers maintains an inverse map of shard id to node id list. This list is kept up to date with cluster topology changes from newly introduced nodes and/or node failures.
Sharding Strategy
At indexing time, the ShardingStrategy is applied from the data events streamed-in from the gateway for each node. So only data-events belong to a specific shard is added. ShardingStrategy can be configured with sensei.sharding.strategy setting in the sensei.properties file.
Load Balancer Factory
At query time, the broker uses the SenseiLoadBalancerFactory to get a SenseiLoadBalancer and generates a routing map to get a list of nodes to send the requests to. By default, broker uses consistent hash on the routing parameter provided by the request. Load balancer factory can be configured with sensei.search.router.factory setting in the sensei.properties file.