To those who are not interested in the technical details of sensei hadoop indexing, you can skip this section and continue the following demo section.
File layout of sensei hadoop indexing system source packages:
com.sensei.indexing.hadoop.job;
This package contains the job configuration file loading classes.
com.sensei.indexing.hadoop.keyvalueformat;
This package specifies the data format (key, value) used in hadoop-indexing system.
com.sensei.indexing.hadoop.map;
This package contains underlying Sensei Hadoop Mapper file and also a dummy Converter to deal with preprocess of input record.
com.sensei.indexing.hadoop.reduce;
This package contains Hadoop Reduer and Combiner files.
com.sensei.indexing.hadoop.util;
Util package has all kinds of naming configuration files and utility tools.
System Workflow:
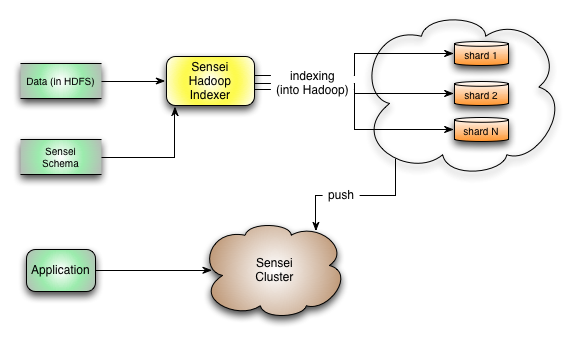
As we can see from the system workflow above, Sensei Hadoop indexer is relatively independent from other Sensei components. Users can sepicfy how many shards as the system output, and also the sharding strategy, input data converter, etc. The generated index can be directly used by Sensei to bootstrap.